Molti avranno visto o sentito parlare gli ultimi mesi di ChatGPT, ma non è solo sul fronte dell’interazione tramite Chat che si stanno avendo grandi progressi con l’intelligenza artificiale.
In questo articolo saremo a spiegare in linea di massima il funzionamento per poi fornire un codice di esempio in Python.
Funzionamento delle reti Stable diffusion e derivate
Le reti Stable diffusion a differenza ad esempio di un modello object detection sono composte principalmente da 2 componenti.
Una parte interpreta il testo per generare degli input che rappresentano cosa dovrà avere l’immagine, quali temi insomma dovrà trattare, mentre la seconda parte partendo da questi input va su vari step in cui viene passato come input l’output stesso a ridurre il rumore dell’immagine ( originariamente puro rumore ).
Riducendo il rumore assieme a degli input che definiscono cosa tratta l’immagine si va di fatto a fare una cosa simile ai primi esperimenti Deep dream, dove essendo moltissimo il rumore, l’immagine finisce per essere inventata di sana pianta.
Nella rete invece che tratteremo nell’articolo ci si è spinti oltre, e non solo si genera un’immagine partendo dal testo, ma suddetto testo invece che essere una descrizione, saranno delle istruzioni che dicono al modello come ritoccare / alterare l’immagine in oggetto.
La rete in questione con cui sono generati gli esempi sotto è stata creata da timbrooks.
Esempi di elaborazioni di foto
Partiamo da questa foto della città di Terni


Come possiamo vedere semplicemente dando queste 2 istruzioni al modello abbiamo ottenuto un risultato niente male, unica cosa curiosa, la parte illuminata del sole è stata trasformata in fuoco.
Perchè invece non pensare come sarebbe questa foto se ci fosse un’inondazione?

Anche qui assolutamente sorprendente il risultato, specialmente i riflessi dell’acqua ed il fatto che le piante , più alte, siano correttamente rimaste fuori dall’acqua
Ora passiamo a cose più folli, e se volessimo una piazza con edifici quasi uguali, ma ambientata nel celebre MMORPG World of Warcraft?
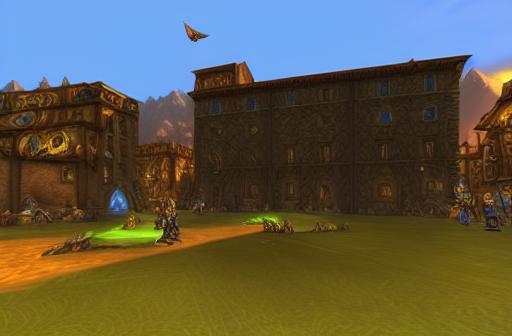
Non serve commentare , anche qui un risultato quasi perfetto a parte alcuni artefatti in alto a sinistra, perfino le finestre sono ste modificate per ricalcare il videogioco così come il terreno che ora ha le texture classiche di World of Warcraft.
Altre richieste sempre sulla stessa immagine, alcune andate clamorosamente male
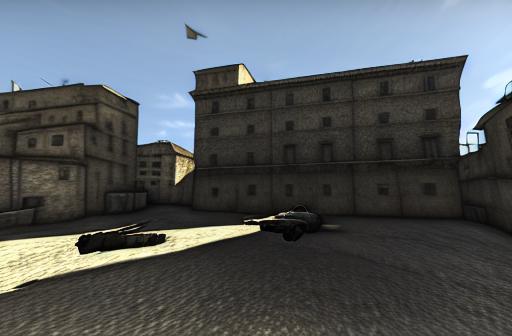

Altra immagine originale




Anche qui non serve commentare sul risultato, assolutamente perfetto
Ora passiamo ad altri compiti che riguardano invece le persone,


Altro esempio estremo

In questo ultimo esempio partendo dall’immagine di sinistra, generata con Stable diffusion ed una descrizione oscena, è stato chiesto in modo intermedio “make it a portrait” in modo di rigenerare delle sembianze umane, poi nel secondo step sono stati chiesti 4 prompt( 4 step ), “make her a pretty girl” “make her face less tall” “change her hair to blond” “make it a photo”
Sorgente tool utilizzato
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import PIL import requests import torch from diffusers import StableDiffusionInstructPix2PixPipeline, EulerAncestralDiscreteScheduler import sys model_id = "timbrooks/instruct-pix2pix" pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16, safety_checker=None) pipe.to("cuda") pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config) url = "https://raw.githubusercontent.com/timothybrooks/instruct-pix2pix/main/imgs/example.jpg" def download_image(filename): image = PIL.Image.open(filename) image = PIL.ImageOps.exif_transpose(image) image = image.convert("RGB") image.thumbnail((512,512), PIL.Image.ANTIALIAS) return image images = [download_image(sys.argv[1]),] for prompt in sys.argv[3:]: image = images[0] images = pipe(prompt, image=image, num_inference_steps=40, image_guidance_scale=1.05).images images[0].save(sys.argv[2]) |
Come dipendenze va insallata la libreria diffusers di huggingface ed assolutamente consigliato, CUDA, senza gpu preparatevi ad aspettare ore per un’immagine invece di pochi secondi!
Altra cosa degna di nota il parametro image_guidance_scale , modificandolo cambia molto il comportamento, più e basso e più la nuova immagine è diversa da quella in input, aumentandolo oltre 1.5 di solito non cambia più nulla sull’immagine.
Esempio di invocazione:
|
1 |
python3 instruct.py test20.jpg test20_1.jpg "make her a pretty girl" "make her face less tall" "change her hair to blond" "make it a photo" |














